
Comparison (benchmark) of GPU cloud platforms and GPU dedicated servers based on NVIDIA cards.
This article represents comparative experience in training a model on different GPU platforms: Google, AWS, and a domestic Dutch hosting provider HOSTKEY. Data science experts from Catalyst have compared the time and monetary investment in training the model and have chosen the best option.
Material prepared by the Catalyst team.

The opinions of the authors expressed herein may not represent those of the publisher.
High-performance GPUs are in high demand today in all areas of the IT industry, in scientific projects, in security systems and other areas. Engineers, architects, and designers need powerful computers for rendering and 3D animation, for training neural networks and data analysis, real-time analytics, and for other tasks involving a large amount of computation. In general, high-performance GPU servers are a very popular solution on the market.
Year over year, methods and applications for Artificial Intelligence (AI) and Machine Learning (ML) are becoming increasingly widespread in all fields. These technologies have already revolutionized the field of medical diagnostics, financial instrument development, the creation of new data processing services, as well as facilitating the implementation of numerous projects in the fields of basic science, robotics, human resource management, transport, heavy industry, urban economy, speech recognition, people and content delivery facilities. For example, NVIDIA encouraged owners of powerful GPU computers to donate their processing power to help combat the COVID-19 coronavirus pandemic.
GPUs as a service
As many modern machine learning tasks use graphics processors, people are increasingly faced with one overarching question: which one should I use? To answer this question, you need to understand the cost and performance indicators of the different GPUs. Currently, there are a number of providers that offer virtual, cloud (GPUaaS) and dedicated GPU servers for machine learning.
Dedicated servers are the best option when you need computing power on an ongoing basis, and when maintaining your own machine is prohibitive or simply impossible. Some providers rent out GPU servers on a monthly basis, and if you have the right workload that can keep the server busy in terms of hours and minutes, then the prices can be very attractive indeed. However, in most cases, virtual servers (VDS / VPS) with by-the-hour or minute billing or cloud services are still the preferred choice as they are usually cheaper and more flexible.

Types of GPUs used in the dedicated GPU server pools of four leading providers (according to Lliftr Cloud Insight, May 2019)
According to the latest Global Market Insights report, the global GPUaaS market will reach $7 billion by 2025. Market participants are developing GPU solutions specifically for Deep Learning (DL) and AI. For example, the NVIDIA Deep Learning SDK provides high-performance GPU acceleration for Deep Learning algorithms and is designed to create off-the-shelf DL frameworks.
GPUaaS companies focus on technological innovation, strategic acquisitions and mergers to strengthen their market position and to stake out market share. Key players in the GPUaaS market include AMD, Autodesk, Amazon Web Services (AWS), Cogeco Communications, Dassault Systems, IBM, Intel, Microsoft, Nimbix, NVIDIA, Penguin Computing, Qualcomm, Siemens, HTC. For Machine Learning, the most popular GPUs are AWS, Google Cloud Engine, IBM Cloud, and Microsoft Azure.
You can also take advantage of the power of graphics accelerators from less well-known providers — their GPU servers can be used in any number of projects. Each platform has its pros and cons. It is believed that high-performance servers with powerful GPUs allow you to quickly achieve your goals and get meaningful results, but are the expensive iterations worth the money, and in what cases?
Learn and learn some more
The process of training a model is more computationally expensive and it requires a lot more resources than is required to execute an already trained model. If the task does not imply some kind of ultra-high load, such as face recognition from a large number of cameras, then just one or two graphics cards of the GeForce GTX 1080 Ti level are enough for most jobs — a key element in managing that project budget. The most powerful modern Tesla V100 GPUs are typically used just for training.
Moreover, the working version of the model might only take up a fraction of the resources of the GPU — meaning that one card can be used to execute several models. However, this approach does not work when training because of the nature of the memory bus device, and also an integer number of graphic accelerators is used for the training of each model. Also, the learning process is often a set of experiments to test hypotheses, when a model is repeatedly trained from scratch using a number of different parameters. These experiments are conveniently run in parallel on adjacent graphics cards.
A model is considered trained when the expected accuracy is achieved, or when the accuracy no longer increases with any further training. Sometimes bottlenecks arise when training models. Ancillary operations like preprocessing and downloading images may take up a lot of processor time. This means that the server configuration was not properly balanced for this particular task: i.e. the CPU is not able to “feed” the GPU efficiently.
This applies as well to dedicated and virtual servers. In a virtual server, the problem can also be caused by the fact that one CPU is actually serving several GPUs. The dedicated processor is at full capacity, but its capabilities may still be insufficient. Simply put, in many tasks the power of the central processor is important as it is needed to process data in the first stage of the task. (see graphic below)

Simplified model training scheme.
Training on multiple (N) GPUs is as follows:
- A set of pictures is taken, divided into N parts and “decomposed” by accelerators;
- In each accelerator, its error rate is calculated for its own set of pictures as well as its future gradient (the direction that the coefficients must go so that the error rate becomes smaller);
- The gradients from all the accelerators are collected by one of them and added up;
- The model takes a step in the averaged direction on one accelerator and learns;
- A new, improved model is then sent to the rest of the GPUs, and it cycles back to step 1 and repeats.
If the model workload is very light, then the execution of N cycles on one GPU is faster than their distribution on N GPUs followed by the combination of the results. The savings can be enormous. Indeed the financial outlay can be significant when engaging in active experiments with a model. For instance, when testing many hypotheses, the calculation time can sometimes last days, and consequently, companies sometimes spend tens of thousands of dollars a month on renting Google servers.
Catalyst to the rescue
Catalyst is a high-level library that allows you to conduct Deep Learning research and develop models faster and more efficiently, reducing the amount of boilerplate code. Catalyst takes over the scaling of the pipelines and provides the ability to quickly and reproducibly train a large number of models. Thus, you can do less programming and focus more on hypothesis testing. The library includes a number of the best industry solutions, as well as ready-made pipelines for classification, detection and segmentation.
Recently, the Catalyst team has partnered with Georgia State University, the Georgia Institute of Technology and the Emory University Joint Center for Translational Research in Neuro-imaging and Data Science (TReNDS) to simplify model training for neuro-imaging applications and provide reproducible Deep Learning studies in the field of brain imaging. Working together on these important issues will help better understand how the brain works and improve the quality of life of people with mental disorders.
Returning to the topic of the article, Catalyst was used in all three cases to check the speed of the servers: on the HOSTKEY, Amazon, and Google servers. Let’s compare how it went.
Ease of use
An important indicator is the usability of the solution. Decidedly few services offer an intuitive virtual server management system with all the necessary libraries as well as instructions on how to use them. When using Google Cloud, for example, you have to install libraries yourself. Here’s a subjective assessment of the web interfaces:
Service Web Interface
AWS Anti-leader: all configurations are encoded with p2.xlarge-style names — to understand what hardware is hidden under each name, you need to go to a separate page, and there are about a hundred of such names
Google Average rating, not a very intuitive setup
Google Colab Jupyter Notebook Analog
HOSTKEY Web service not used
In fact, to start using these tools, it takes about 20–60 minutes (depending on your qualifications) to prepare — install the software and download the data. As for the convenience of using pre-released, ready-to-use instances, the situation here is as follows:
Service Software Suite
AWS The absolute leader, each instance contains every popular version of machine learning libraries as well as a pre-installed NVIDIA-Docker. There is a Readme file with a brief instruction on how to switch between the myriad of versions.
Google Comparable to HOSTKEY, but you can mount your Google-drive and thus have very quick access to the data set without needing to transfer it to the instance.
Google Colab Offered for free, but once every 6–10 hours the instance dies. The software is completely absent, including a Docker + NVIDIA-Docker2 along with the ability to install them, although you can do without them. There is no direct SSH connection, but quick access to your Google drive is possible.
HOSTKEY The server can be provided both without software and already fully configured. For self-tuning, you can use the software in the form of a Docker + NVIDIA-Docker2. For an experienced user, this is not a problem.
Results of the experiment
A team of experts from the Catalyst project conducted a comparative test of the cost and speed of training a model using the NVIDIA GPU on servers from the following providers: HOSTKEY (from one to three GeForce GTX 1080 Ti GPUs + Xeon E3), Google (Tesla T4) and AWS (Tesla K80). The tests used the standard ResNet architecture for these kinds computer vision tasks, which determined the names of artists from their paintings.
In the case of HOSTKEY, there were two accommodation options. First: a physical machine with one or three video cards, Intel Xeon E5–2637 v4 CPU (4/8, 3.5 / 3.7 GHz, 15 MB cache), 16 GB RAM and 240 GB SSD. Second: a virtual dedicated VDS server in the same configuration with one video card. The only difference was that in the second case, the physical server had eight cards at once, but only one of them was given over to the full disposal of the client. All the servers were located in their data center in the Netherlands.
The instances of both cloud providers were launched in Frankfurt am Main data centers. In the case of AWS, the p2.xlarge type was used, equipped with Tesla K80, 4 vCPU, 61 GB RAM. Part of its computer time was spent on data preparation. A similar situation occurred in the Google cloud, where an instance with 4 vCPUs and 32 GB of memory was used, to which an accelerator was added. The Tesla T4 card, even if it was focused on inference, was chosen because by performance in training it is somewhere between the GTX 1080 Ti and the Tesla V100. In practice it is still sometimes used for training as it costs much less than the V100.
Comparison of the machine learning times and the costs of model training on different platforms

The model was used in two versions: “heavy” (resnet101) and “light” (resnet34). The heavy version has the best potential for achieving high accuracy, while the light version gives a larger performance increase with slightly more errors. Heavier models are usually used where it is critical to achieve maximum predictive results, for example, when participating in competitions, while light ones are used in places where it is necessary to achieve a balance between accuracy and processing speed, for example, in loaded systems that process tens of thousands of requests daily.
Training cost, USD / training time, heavy model

x-axis — time, sec y-axis — cost, USD
The cost of training a model on a HOSTKEY server with its “in-house” default cards is almost an order of magnitude cheaper than in the case of Google or Amazon, though it takes slightly more time. Furthermore, this is despite the fact that the GeForce GTX 1080 Ti is far from the fastest card for solving deep learning tasks today. However, as the experimental results show that, in general, inexpensive cards like the GeForce GTX 1080 Ti are no so worse than their more expensive counterparts in terms of speed, regardless of their significantly lower cost.
Training cost, USD / training time, light model
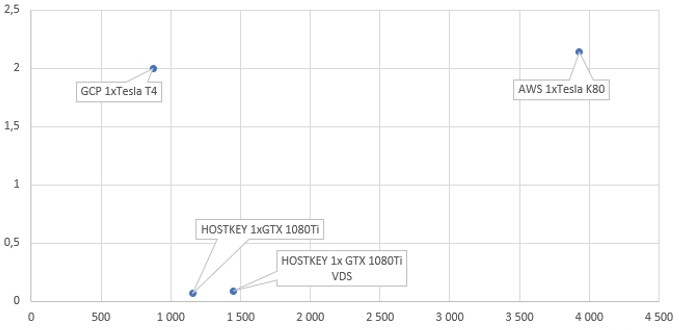
x-axis — time, sec y-axis — cost, USD
If the card is an order of magnitude cheaper, then in performance on heavy models it is only 2–3 times inferior, and you can accelerate the whole process by adding more cards. In any case, this solution will be cheaper than Tesla configurations in terms of the cost of training the model. The results also show that the Tesla K80 in AWS, which demonstrates high performance in double-precision computing, shows a very long time at single precision — worse than the 1080 Ti.
Conclusion
The general trend is this: cheaper consumer-level graphics cards provide overall better value for money than Tesla’s expensive GPUs. The deficiency in the sheer speed of the GTX 1080 Ti when compared to Tesla can be compensated for by an increase in the number of cards, thus eliminating any advantage in using the Tesla.
If you plan to perform a computer-heavy task, servers with inexpensive GTX 1080 Ti are more than enough. They are suitable for users who plan long-term work with these resources. Expensive Tesla-based instances should be selected only in cases where model training takes little time and you can pay for work by the minute of training.
Finally, one should also consider the simplicity of preparing the environment on the platforms — installing libraries, deploying software and downloading data. GPU servers — both real and virtual — are still noticeably more expensive than classic CPU instances, so long preparation times may lead to increased cost.




